
Hallo, ich heiße Matthias Zeis - schön, dass Sie den Weg zu meiner Übersetzung von ZFSTDE gefunden haben!
Falls Sie mehr über Magento 2 oder meine Arbeit als Technical Lead bei LimeSoda erfahren möchten, kommen Sie doch auf meiner Website vorbei.
Hallo, ich heiße Matthias Zeis - schön, dass Sie den Weg zu meiner Übersetzung von ZFSTDE gefunden haben!
Falls Sie mehr über Magento 2 oder meine Arbeit als Technical Lead bei LimeSoda erfahren möchten, kommen Sie doch auf meiner Website vorbei.
Inhaltsverzeichnis
Bei der Optimierung der Leistung geht es nicht darum, alle doppelten Anführungszeichen durch einfache Anführungszeichen zu ersetzen und dafür zu beten, dass die wenigen eingesparten Nanosekunden Apache davon abhalten, sich in den Swap-Speicher zu verbeißen und Ihren Server in Flammen aufgehen zu lassen, wenn Sie auf Digg gelistet werden. Es handelt sich vielmehr um einen wohldurchdachten Prozess, in dem man Performance-Ziele setzt, Benchmarks durchführt, um die aktuelle Leistung zu erheben, Ineffizienzen und Flaschenhälse identifiziert, angemessene Serverhardware ankauft und in dem man offensiv neue Taktiken ausprobiert, die einem vorher nie in den Sinn gekommen sind. Mit anderen Worten ist es eine Menge Spaß!
Ich diskutiere in diesem Anhang die Leistungsoptimierung in Form verschiedener Ansätze und Taktiken, die in der realen Welt häufig verwendet werden - in der wir uns nicht wirklich um Zeug wie doppelte Anführungszeichen kümmern müssen (ausgenommen der Fall, dass sie einen wahrnehmbaren Effekt erzielen). Die meisten davon sollten für Sie gute Freunde werden, falls sie das nicht schon sind.
Da es eine umfangreiche Aufgabe ist, alle Optionen zur Leistungsverbesserung darzulegen, ist dies auch ein umfangreicher Anhang, aber er kommt Ihnen hoffentlich gelegen. Ich werde dieses Kapitel nicht nur auf das Zend Framework beschränken: ein großer Teil dieses Anhang trifft auf jede PHP-Anwendung zu.
Bevor wir irgendwas tun, sollten wir uns klar darüber sein, dass Sie ein einwandfreies Anwendungsdesign niemals auf dem Altar der vorzeitigen Optimierung opfern sollten. Vorzeitige Optimierung ist - wie Sr. Tony Hoare es ursprünglich formuliert hat - die Wurzel alles Bösen. Aber lassen Sie uns das nicht aus dem Kontext reißen! Wenn wir Optimierungen ewig hinausschieben, werden wir auch nie eine effiziente Anwendung erhalten. Man ist oft gefährdert, der Versuchung zu erliegen, doch das richtige Timing ist hier essentiell. Wenn man zu früh optimiert, kann dies zu einem restriktiven Design führen, das nur noch mehr Probleme verursacht; daher ist es die Sache wert zu warten, bis sich die Anwendung in einem Status befindet, indem sie für Optimierungen bereit ist.
Optimierung ist ein Spiel, in dem messbare Ineffizienzen eliminiert werden. Das Stichwort ist "messbar". Wenn Sie die Auswirkung einer Optimierung nicht verlässlich messen oder vorhersagen können, wie wissen Sie dann, ob es eine lohnenswerte Optimierung ist? Dumm ein paar doppelte Anführungszeichen durch einfache Anführungszeichen zu ersetzen benötigt vielleicht eine Mannstunde und führt zu einem überhaupt nicht bemerkbaren Leistungszuwachs. Sie haben eine Stunde verschwendet und haben wenig oder sogar gar nichts erreicht, mit dem Sie prahlen können! Zugleich gibt es es vielleicht ein langsames SQL-Statement, bei dem Sie mittels Caching mittels Zend_Cache dank weniger Minuten Arbeit eine ganze Sekunde einsparen können. Die zweite Option verdient eindeutig mehr Aufmerksamkeit. Fokussieren Sie ihre Bemühungen auf jene Optimierungen, die den größten Nutzen bringen.
Es gibt drei Herangehensweise an die Optimierung: Sie folgen Ihrem blinden Glauben, Sie folgen Ihrer Intuition, die Sie durch Erfahrung erworben haben, oder Sie setzen Softwaretools ein, um Ihre Anwendungen und deren Optimierungsmöglichkeiten zu analysieren. Nur die dritte Option ist wirklich zulässig. Die anderen sind mit Unsicherheiten behaftet und Sie riskieren durch sie, wertvolle Optimierungsmöglichkeiten unentdeckt zu lassen oder Ihre Zeit mit nutzlosen Optimierungsversuchen zu verschwenden. Die ersten beiden sollten dadurch nicht völlig entwertet werden, aber die Optimierungen dort gehören oft jener Kategorie an, die jeder vernünftige Programmierer über die gesamte Entwicklung hinweg anwenden sollten - es handelt sich nicht um Bereiche, mit denen man sich nachträglich stundenlang beschäftigen sollte.
Ein erfahrener Programmer wird selten eine richtig ineffiziente Anwendung fabrizieren, die von offensichtlichen Codemängeln durchzogen ist. Einige Elemente der Leistungsoptimierung werden im existierenden Design bereits umgesetzt sein, womit man Fortschritte nur noch mit gut durchdachten Maßnahmen erzielt. Viele Optimierungen sind allgemein bekannt, da es - sobald man das Problem verstanden hat - nur eine endliche Anzahl an Lösungen gibt aus denen man auswählen kann, und über die meisten davon hat bereits der halbe Planet gebloggt.
Optimierung funktioniert nur, wenn Sie signifikant messbare Ergebnisse erzielen können. Signifikanz ist natürlich relativ: für den einen Programmierer kann es eine Millisekunde sein, für den anderen eine Sekunde. Wenn man die offensichtlichsten Performanceprobleme beseitigt hat, werden immer weniger Möglichkeiten bis an die Oberfläche vorstoßen, bis man einen Punkt erreicht, an dem weitere Optimierungen höhere Kosten verursachen, als daraus Nutzen entsteht oder als die Anschaffung teurer Hardware kostet. Sie sollten in jedem Fall ein Performance-Ziel setzen. Um dieses Ziel zu erreichen, muss man die aktuelle Leistung als Ausgangspunkt erheben und in Zukunft immer wieder Messungen vornehmen, um festzustellen, ob gegenüber dem Ausgangswert lohnenswerte Verbesserungen erzielt werden konnten.
Zur Erfassung der Leistung gibt es einige Metriken. Die Auslastung des Speichers und der CPU sind offensichtliche Werte, besonders bei einem einzelnen Server, auf dem die Ressourcen begrenzt sind. Doch auch in einer Umgebung, in der Sie Ihre Hwardware vertikal oder horizontal skalieren, kann die Maximierung der Leistung Sie davor bewahren unnötig tief in die Tasche zu greifen, um mit teuren Servern Löcher in suboptimalem Code zu stopfen. Einen weiteren gebräuchlichen Messwert stellen die Anfragen pro Sekunde dar: ein Maß, welches angibt, wieviele Anfragen ein Teil Ihrer Anwendung mit der gegebenen Hardware abarbeiten kann.
Die Erfassung des Speicherverbrauchs kann sowohl auf dem Server- als auf dem PHP-Level gemessen werden. PHP bietet zwei nützliche Funktionen, die messen, wie viel Speicher PHP konsumiert. memory_get_usage() und memory_get_peak_usage() können aufgerufen werden um festzustellen, wie viele Bytes entweder zu einem bestimmten Zeitpunkt oder am speicherhungrigsten Punkt im PHP-Workflow konsumiert wurden. Sie werden üblicherweise verwendet, um einige ungefähre Schätzung des Speicherprofils einer Anwendung zu erhalten - um festzustellen, an welchen Stellen der Anwendung der Speicherbedarf einen definierten Toleranzbereich überschreitet. Diesen Toleranzbereich festzulegen ist keine einfache Aufgabe, da bestimmte Funktionalitäten von Natur aus speicherhungriger als andere sind. Es hat seinen Grund, warum in Ihrer php.ini-Datei recht hohe Limits gesetzt sind!
Zuallererst sollten wir uns darüber einig sein, dass es sinnlos ist, sich an manuellen Messungen zu versuchen. Anstatt dass Sie auf jeden möglichen Link klicken und jedes Formular per Hand abschicken, setzen Sie einen oder mehrere Punkte im Quelltext fest, an dem Messungen stattfinden können. Es liegt bei Ihnen, ob Sie ein Softwaretool verwenden, das automatisch alle Routen abgeht (falls Sie funktionales Testing einsetzen, wäre das ein guter Startpunkt) oder ob Sie einen Beta-Sticker auf Ihre Livesite klatschen und die Anwendung für eine kurze Zeit laufen lassen.
Eine mögliche provisorische Lösung ist, ein kleines Controller-Plugin zu schreiben, welches die Methode Zend_Controller_Plugin_Abstract::dispatchLoopShutdown() implementiert.
<?php class ZFExt_Controller_Plugin_MemoryPeakUsageLog extends Zend_Controller_Plugin_Abstract{ protected $_log = null; public function __construct(Zend_Log $log) { $this->_log = $log; } public function dispatchLoopShutdown() { $peakUsage = memory_get_peak_usage(true); $url = $this->getRequest()->getRequestUri(); $this->_log->info($peakUsage . ' bytes ' . $url); } }Sie können das Plugin in Ihrer Bootstrap registrieren, wenn Sie es verwenden möchten.
<?php class ZFExt_Bootstrap{ // ... public function enableMemoryUsageLogging() { $writer = new Zend_Log_Writer_Stream( self::$root . '/logs/memory_usage'); $log = new Zend_Log($writer); $plugin = new ZFExt_Controller_Plugin_MemoryPeakUsageLog($log); /** * Setzen Sie einen hohen Stack-index, um die Ausführung zu * verzögern, bis andere Plugins ihre Arbeit verrichtet haben * und ihr Speicherverbrauch ebenfalls berücksichtigt werden * kann. */ self::$frontController->registerPlugin($plugin, 100); } // ... }Dieses Beispiel ist ziemlich einfach gehalten. Sie könntn es leicht erweitern, so dass zusätzliche Informationen über die Anfrage geloggt werden, damit Sie genug Daten haben, um die Anfrage in einer kontrollierteren Umgebung zu wiederholen und die Ursache für den hohen Speicherbedarf zu eruieren. Hier sehen Sie einige Ausgaben des obigen Log-Setups:
2009-01-09T15:41:46+00:00 INFO (6): 4102728 bytes / 2009-01-09T15:42:57+00:00 INFO (6): 4103608 bytes /index/comments
Wenn Sie den Speicherverbrauch lieber fortlaufend sehen wollen, können Sie einen anderen PHP-Stream als Writer auswählen oder gar den Firebug-Writer verwenden, um die Live-Ergebnisse zu beobachten, wenn Sie Firefox mit FirePHP verwenden.
Sobald Sie ein grobes Speicherprofil zur Hand haben, können Sie einen systematischeren Ansatz wie Code-Profiling verwenden, um Details zu den Ursachen des Speicherverbrauchs zu sammeln. Code-Profiling ist auch eine gute Methode um festzustellen, wo die meiste Ausführungszeit verbraucht wird.
Abseits von in den Anwendungen eingebauten Lösungen können Sie den Speicher- und CPU-Bedarf auf dem Server selbst durch verschiedene Tools überwachen. Linuxsysteme bieten unter anderem die Programme top, free und vmstat an. Einer meiner persönlichen Favoriten ist htop, das eine ständig aktualisierte Zusammenfassung der Speicher- und CPU-Auslastung sowie Daten für jeden Prozess anzeigt und einige interaktive Features wie das Ordnen der Prozesse nach verschiedenen Statistiken bietet.
Diese Tools sind besonders wertvoll, wenn Sie Ihren Server speziell für Ihre Anwendung tunen, aber Sie können Sie auch dabei unterstützen zu untersuchen, wie Ihre Anwendung auf einem noch nicht optimierten Testserver während eines Lasttests funktioniert - wie viel Speicher konsumieren die Apache-Prozesse, kann ich mehr oder weniger Apache-Clients laufen lassen, welche Anwendungen belasten die CPU stärker als den RAM?
Load-Testing ist ein weiteres nützliches Werkzeug zur Leistungsmessung. Es wird in signifikantem Ausmaß durch die Hardware beeinflusst, auf der die Tests ausgeführt werden; um vergleichbare Resultate zu erhalten, müssen Sie ein Testsystem verwenden, dessen Spezifikationen und Rahmenbedingungen konstant bleiben. Die Absicht ist zu messen, wieviele Anfragen Ihre Anwendung (eine bestimmte URL oder eine Gruppe von URLs) pro Sekunde im Durchschnitt abschließen kann. Die benötigte Zeit ist weniger interessant (sie ändert sich mit der Hardware); vielmehr ist die relative Veränderung zwischen den Messungen ein Indikator dafür, ob sich die Leistung Ihrer Anwendung verbessert oder verschlechtert. Sie werden feststellen, dass die meisten Framework-Benchmarks diesem Wert hinterhereifern.
Der Ansatz ist die Situation zu simulieren, dass eine bestimmte Anzahl von Anfragen verteilt über eine bestimmte Anzahl gleichzeitiger Benutzer an den Server gestellt wird. Manchmal wird als Basiselement auch eine Zeitspanne anstatt einer fixen Zahl von Anfragen gewählt. Die Gesamtzahl aller bedienten Anfragen wird dann durch die Zeit in Sekunden dividiert, die zur Abfertigung der Requests benötigt wurde. Es handelt sich um ein sehr effektives Tool zur Kontrolle von Veränderungen der Anwendungsleistung, wenn man die Anwendung und/oder den Server optimiert.
Zwei häufig für diesen Zweck verwendete Werkzeuge sind ApacheBench (ab) und Siege.
Das Tool ApacheBench wird normalerweise gemeinsam mit den Binärdateien des HTTP-Servers installiert. Falls die Datei fehlt, müssen Sie eventuell das Paket Apache Utils installieren. Unter Ubuntu ist das Programm üblicherweise unter /usr/sbin/ab zu finden. Das Verzeichnis ist standardmäßig nicht in Ubuntus PATH aufgelistet, was bedeutet, dass Sie /usr/sbin entweder zum PATH Ihres aktuellen Benutzers hinzufügen oder es über den absoluten Pfad aufrufen sollten.
Dies ist der ApacheBench-Befehl, um 10,000 Anfragen über 100 simulierte gleichzeitige Benutzer abzusetzen (der Schrägstrich am Ende ist bei "nackten" URIs wichtig):
ab -n 10000 -c 100 http://www.survivethedeepend.com/
Die daraus resultierende Ausgabe wird dieser ähnlich sein::
Server Software: apache2
Server Hostname: www.survivethedeepend.com
Server Port: 80
Document Path: /
Document Length: 9929 bytes
Concurrency Level: 100
Time taken for tests: 341.355 seconds
Complete requests: 10000
Failed requests: 0
Write errors: 0
Total transferred: 101160000 bytes
HTML transferred: 99290000 bytes
Requests per second: 29.29 [#/sec] (mean)
Time per request: 3413.555 [ms] (mean)
Time per request: 34.136 [ms] (mean, across all concurrent requests)
Transfer rate: 289.40 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 1.7 0 52
Processing: 124 3409 831.1 3312 10745
Waiting: 120 3267 818.5 3168 10745
Total: 124 3409 831.1 3312 10745
Percentage of the requests served within a certain time (ms)
50% 3312
66% 3592
75% 3784
80% 3924
90% 4344
95% 4828
98% 5576
99% 6284
100% 10745 (longest request)
Hier sehen Sie ein ähnliches Beispiel für Siege, wobei Sie die Gesamtzahl der Anfragen setzen, indem Sie eine Anzahl der gleichzeitigen Benutzer mit einem Wiederholungsfaktor für jeden Benutzer festlegen. 100 gleichzeitige Benutzer, die ihre Anfrage 10-mal wiederholen, ergeben somit insgesamt 1,000 Anfragen. Die zusätzliche Option legt eine Pause von einer Sekunde zwischen den gleichzeitigen Benutzern fest, was für einen Leistungstest ausreicht.
siege -c 100 -r 10 -d 1 http://www.survivethedeepend.com
Es wird etwas weniger ausgegeben, aber die Anfragen pro Sekunde werden auch hier als "Transaction rate" ausgegeben:
Transactions: 1000 hits Availability: 100.00 % Elapsed time: 43.77 secs Data transferred: 3.06 MB Response time: 3.20 secs Transaction rate: 22.85 trans/sec Throughput: 0.07 MB/sec Concurrency: 73.08 Successful transactions: 1000 Failed transactions: 0 Longest transaction: 8.78 Shortest transaction: 0.05
Beide Tools bieten eine Reihe an weiteren Optionen, bei denen sich eine weitere Beschäftigung lohnt. Wenn der Zeitpunkt der Auslieferung näherkommt, kann die Kombination ähnlicher Tests mit einem Monitoring der Server-Ressourcen wie dem Speicherverbrauch und der CPU-Auslastung sehr informativ und nützlich sein, um die Konfiguration von Apache zu optimieren.
Und ja, die Performance der Website zu diesem Buch war miserabel, als ich die Loadtests laufen ließ! Hätte ich die Seiten damals richtig gecacht, dann wären die Anfragezeiten signifikant niedriger gewesen.
Ich möchte nochmals anmerken, dass Load-Testing sowohl die Software als auch die Hardware berücksichtigt und es sich daher um ein nützliches Werkzeug handelt, um neben der Leistung der Anwendung auch den Server zu optimieren.
Anstatt nach dem Zufallsprinzip Codeteile herauszupicken, diese zu optimieren und die Finger zu kreuzen, dass die Maßnahme etwas gebracht hat, finden Sie hier einige Methoden, mit denen man tatsächliche Performanceprobleme identifizieren kann.
Indem man Load-Testing durchführt und die Ressourcen überwacht, kann man sich einen Gesamteindruck darüber verschaffen, welche Teile der Anwendung schlechter oder besser laufen. Wenn man ein Performanceproblem findet, gibt es aber nur einen definitiven Weg, um die Ursache dafür zu lokalisieren: man muss die Performance über den gesamten ausgeführten Code dieses Teils der Anwendung hinunterbrechen. Bei einer einfachen Anwendung reicht es vielleicht aus, den Quelltext zu lesen, aber komplexe Anwendungen wirbeln nur so durch Datenbankoperationen, die Verarbeitung von Dateien und unzählige andere Tätigkeiten, die sich auf die Leistung auswirken. Wenn Sie daran denken, dass Ihre Anwendung womöglich auch noch Bibliotheken von Dritten einsetzt, dann ist das Lesen des Codes nicht so einfach, wie es klingt.
Code-Profiling oder Method-Timing bezeichnet die Vorgangsweise, einen einzelnen Request so herunterzubrechen, dass man die Ausführungszeit und den Speicherverbrauch jedes Funktions- oder Methodenaufrufs einer Anfrage untersuchen kann. Sein Wert ist unschätzbar, wenn es darum geht, Performanceprobleme zu diagnostizieren und Ziele für Optimierungsmaßnahmen zu identifizieren.
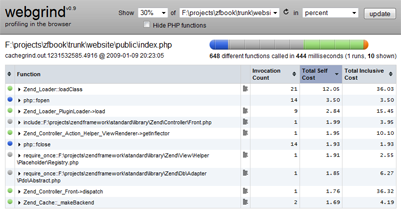
Ein häufig verwendeter PHP-Profiler ist die von Derick Rethans gewartete Erweiterung Xdebug. Xdebug stellt Funktionen wie Debugging, Profiling und Analysen zur Codeabdeckung zur Verfügung. Die Profiling-Funktion generiert zu cachegrind kompatible Dateien, die von cachegrind-kompatiblen Anwendungen wie KCacheGrind (KDE), WinCacheGrind (Win32) oder der Webanwendung Webgrind in lesbare Daten verarbeitet werden können.
Je nachdem welche cachegrind-Anwendung man wählt, hat man verschiedene Möglichkeiten zu analysieren, wieviel Zeit in jeder Funktion, Methode und jedem Keyword-Statement verbracht wurde. Einleuchtenderweise sollte man Einsparungspotentiale zuerst dort überprüfen, wo die größten Kosten in Bezug auf Ausführungszeit oder Speicher enstehen. Vielleicht können diese Anwendungsteile optimiert werden, um wesentliche Verbesserungen zu erzielen.
Die aktuelle Version ist über PECL erhältlich. Sie können es mit einem einfachen Befehl installieren:
pecl install xdebug
Dieser Befehl lädt Xdebug herunter und kompiliert es. Falls Sie mit Windows unterwegs sind, finden Sie auf der Downloadseite der Xdebug-Website vorkompilierte Dateien.
Um die Installation abzuschließen, konfigurieren wir Xdebug für das Profiling, indem wir die folgenden Zeilen zu Ihrer Datei php.ini hinzufügen und vorhergehende Zeilen mit den Konfigurationsoptionen zend_extension oder zend_extension_ts auskommentieren oder ersetzen. Hier haben wir eine Beispielkonfiguration für ein Ubuntu-System in /etc/php/conf.d/xdebug.ini (Ubuntu erlaubt erweiterungsspezifische ini-Dateien außerhalb von /etc/php5/apache2/php.ini).
; Xdebug zend_extension = /usr/lib/php5/20060613/xdebug.so ;xdebug.profiler_enable = 1 xdebug.profiler_output_dir = "/tmp" xdebug.profiler_output_name = "cachegrind.out.%t.%p"
Wenn Sie das Profiling starten wollen, dann entfernen Sie den Strichpunkt am Beginn der Zeile mit xdebug.profiler_enable. Fügen Sie Ihn wieder ein, wenn Sie fertig sind - außer Sie mögen es, wenn gigantische cachegrind-Dateien Ihre Festplatte übernehmen. Hier sehen Sie ein Beispiel von Webgrind auf einem Windowssystem: angezeigt werden die Ausführungszeiten pro Funktion/Methode in Prozent.
Um Webgrind zu installieren, müssen Sie die heruntergeladenen Dateien nur in den Document-Root Ihres Apache kopieren und die Datei config.php editieren, um die Optionen $storageDir und $storageProfiler zu entfernen (die ini-Konfiguration von Xdebug weiter oben reicht aus, damit Webgrind diese Pfade automatisch finden kann). Die obige Konfiguration mit xdebug.profiler_output_name sollte reichen, um cachegrind-Ausgaben von Xdebug zu finden.
Indem wir Code-Profiling einsetzen und cachegrind-Dateien für verschiedene URLs der Anwendungen generieren, können wir den Quelltext in Augenschein nehmen um herauszufinden, wer ungezogen ist und die meiste Zeit zur Ausführung benötigt. Im Diagramm können Sie sehen, dass Zend_Loader scheinbar viel Spaß dabei hat, nahezu 25% der Ausführungszeit der Indexseite für sich zu beanspruchen. 25% sind eindeutig genug, damit man diesem Punkt Aufmerksamkeit schenkt!
Xdebug schlüsselt die Codeausführung auf, aber es gibt zusätzliche Alternativen und ergänzende Praktiken, um Optimierungsmöglichkeiten aufzuspüren. Eines der naheliegendsten Ziele ist die Datenbank.
Die Verbindung zu einer Datenbank bringt ein paar Herausforderungen mit sich. Vor allem sind Datenbankoperationen von Haus aus teuer. Ihre Anwendung muss eine Verbindung zum Datenbankserver öffnen, die Abfrage senden, warten bis die Datenbank die Anfrage abgearbeitet hat, das Ergebnis auslesen, noch ein paar weitere spannende Tätigkeiten erledigen, und wirklich...es ist einfach nur ein Durcheinander! Die Datenbank stellt in jeder Webanwendung einen erheblichen Engpass dar, der einen großen Zeit der Ausführungszeit für sich beansprucht.
Optimierungen kann man erzielen, indem man sich damit auseinandersetzt, wie auf die Datenbank zugegriffen und wie sie verwendet wird. Im Fall des Zend Framework umfasst das Zend_Db_Table und Ihre Models, die Komplexität und die Verarbeitungsanforderungen von SQL-Satements sowie die Größe der Ergebnismenge, die von der Datenbank zurückgegeben wird.
In beinahe allen drei Fällen gibt es offensichtliche Optimierungspotentiale und messbare Einsparungsziele. Caching ist dabei jene Strategie, die Vorteile verspricht, wenn sich die abgefragten Daten selten ändern und die Ergebnismenge groß oder das Ergebnis einer langsamen Abfrage ist. Warum sollte man die Datenbank kontinuierlich mit Anfragen nach Daten bombardieren, welche sich nur alle paar Stunden, Tage oder gar Wochen ändern? Cachen Sie sie! Caching im RAM mittels APC oder memcached wäre klarerweise zu bevorzugen, aber ein Dateicache wird reichen, falls die Speicherressourcen knapp sind. Setzen Sie einen angemessenen Gültigkeitszeitraum oder löschen Sie die gecachten Daten manuell, wenn sie sich ändern. Zend_Cache macht die Organisation so einfach wie einen Sonntagsspaziergang im Park. Hier haben wir ein Beispiel mit einem einfachen Comments-Model, dessen Cache-Konfiguration von der Hauptkonfiguration der Anwendung, config.ini, geregelt wird.
[general] ; SQL Query Cache cache.sql.frontend.name=Core cache.sql.frontend.options.lifetime=7200 cache.sql.frontend.options.automatic_serialization=true cache.sql.backend.name=File cache.sql.backend.options.cache_dir=/cache/sql
<?php class Comments extends Zend_Db_Table{ protected $_name = 'comments'; protected $_cache = null; public function init() { /** * Allgemeine Abschnitte von config.ini werden in Zend_Registry * gespeichert. Die statischen Aufrufe würden im Idealfall durch * Dependency Injection ersetzt werden. */ $options = Zend_Registry::get('configuration')->cache->sql; $options->backend->options->cache_dir = ZFExt_Bootstrap::$root . $options->backend->options->cache_dir; $this->_cache = Zend_Cache::factory( $options->frontend->name, $options->backend->name, $options->frontend->options->toArray(), $options->backend->options->toArray() ); } public function getComments($id) { /* * Beziehe die Daten aus dem Cache oder frage sie aus der Datenbank ab * und cache das Ergebnis. */ if (!$result = $this->_cache->load('ENTRY_COMMENTS_' . $id)) { $select = $this->select() ->where('entry_id = ?',$id) ->where('status = ?','approved') ->where('type = ?','comment') ->order('date ASC'); $result = $this->fetchAll($select); $this->_cache->save($result, 'ENTRY_COMMENTS_' . $id); } return $result; } public function insert($data) { /* * Erkläre den existierenden Cache für ungültig, wenn neue Kommentare * gespeichert werden. */ $this->_cache->remove('ENTRY_COMMENTS_' . $data['entry_id']); return parent::insert($data); } }Wenn sich die Daten ständig ändern, wie es bei dynamischen, benutzergenerierten oder auf Einstellungen des Benutzers beruhenden Inhalten der Fall ist, wird Caching nur einen kleinen Vorteil bringen. Der Cache ist vielleicht sogar schon wieder ungültig, bevor Zend_Cache das Schreiben abgeschlossen hat! In diesem Szenario müssen Sie untersuchen, ob das Ersetzen von Zend_Db_Table durch direkteres SQL oder die Umformulierung des SQL-Statements selbst zu einer merkbaren Leistungssteigerung führt. Wenn dieses Problem zusammen mit großen Ergebnismengen auftritt, achten Sie genau darauf, dass Sie wirklich nur die benötigten Daten beziehen. Es macht keinen Sinn, zusätzliche Felder abzufragen, wenn sie nie verwendet werden, da sie nichts tun als Speicher zu belegen und dazu beizutragen, dass Ihr Server nach wertvollem RAM dürstet.
Ein Bereich, dem Sie zum Beispiel besondere Aufmerksamkeit schenken können, ist der "MySQL Slow Query Log". Sie können für dieses Feature mittels der Konfigurationsoption long_query_time eine Ausführungszeit festlegen, ab der Abfragen als langsam definiert werden. Alle langsamen Abfragen können dann für weitere Untersuchungen geloggt werden. Da langsame Abfragen in realer (absoluter) Zeit gemessen werden, sei angemerkt, dass das Load-Testing einer Anwendung die Erkennungsrate erhöhen wird, da die CPU- und die Speicherressourcen stärker ausgelastet werden. Verwenden Sie einen niedrigen Wert für long_query_time, wenn Sie sich auf einen Log Ihres Entwicklungssystems verlassen.
Das Zend Framework bietet mit Zend_Db_Profiler eine eigene Logging-Lösung an, um ein Profil aller SQL-Abfragen und ihrer Ausführungszeiten zu erstellen. Der Profiler kann aktiviert werden, indem dem Konstruktor des Datenbankadapters in den Optionen eine Option mit dem Namen "profiler" und dem Boole'schen Wert TRUE übergeben wird. Danach können Sie die Klasse Zend_Db_Profiler instantiieren und verschiedene Methoden verwenden, um zu untersuchen, für wieviele Anfragen ein Profil erstellt wurde bzw. wie lange die Ausführung gedauert hat, und um ein Array der Abfrageprofile zu erhalten, auf das dann mittels der begleitenden Filter eine noch tiefergehende Analyse angewandt werden kann. Es gibt sogar eine spezielle Klasse Zend_Db_Profiler_Firebug, mit der Sie über die Firebug-Konsole in Firefox eine ständige Kontrolle der Daten durchführen können.
PHP besitzt einige gut bekannte und einige weniger bekannte Optimierungsmöglichkeiten, die nun als gängie Praxis angesehen werden. Einige von ihnen gewannen während des Lebenszyklus von PHP 5.2 an Bedeutung.
Die Verwendung eines Opcode-Cache wie der Erweiterung Alternative PHP Cache (APC) kann signifikante Auswirkungen auf die Leistung jeder PHP-Anwendung haben, indem der Zwischencode gecacht wird, der aus dem Parsing des PHP-Quelltexts entsteht. Wird dieser Schritt der Verarbeitung übersprungen und stattdessen bei den folgenden Anfragen der optimierte Cache wiederverwendet, spart man Speicher und verbessert die Ausführungszeit. Solange man nicht auf einem limitierten "Shared Host" festsitzt, sollte man den Cache auf jeden Fall installieren.
APC lässt sich mittels pecl sehr einfach einstallieren. Unter Linux verwenden Sie:
pecl install apc
Windows-Benutzer können eine vorkompilierte DLL von http://pecl4win.php.net herunterladen.
Im letzten Schritt wird die APC-Konfiguration zu Ihrer php.ini-Datei hinzugefügt oder im typischen Ubuntu-Setup eine neue Datei apc.ini für APC unter /etc/php5/conf.d/apc.ini erstellt.
;APC extension=apc.so apc.shm_size = 50
Die Konfiguration, die Sie verwenden, kann weitere Effekte auf die Leistung haben und ich empfehle Ihnen, die Dokumentation unter http://php.net/manual/en/apc.configuration.php zu lesen. Achten Sie besonders auf apc.shm_size, apc.slam_defense (oder apc.write_lock), apc.stat und apc.include_once_override. Sie sollten sich vergewissern, dass apc.shm_size zumindest auf einen Wert gesetzt ist, bei dem alle von Ihrer Anwendung verwendeten Klassen gecacht werden (oder was auch immer Sie hosten!). Denken Sie auch an alles, was Sie dort über Zend_Cache oder die apc-Funktionen einlagern.
Eine der jüngeren Neuerungen, die in die Konfiguration von php.ini Einzug gehalten haben, ist ein realpath-Cache, der sein Debüt mit PHP 5.2.0 gegeben hat. Dieser speichert die realpath-Werte von relativen Pfaden, die in include_once- und require_once-Statements verwendet werden. In den schlechten alten Zeiten wurde jedes Mal, wenn man require_once mit einem relativen Pfad aufgerufen hat, eine Reihe von Dateioperationen ausgelöst, um die entsprechende Datei zu finden. Nun wird das nur noch einmal gemacht und das Ergebnis anschließend für zukünftige Aufrufe über die angegebene TTL hinweg gecacht.
Die relevanten Einstellungen sind realpath_cache_size und realpath_cache_ttl. Die erste Einstellung bestimmt die Größe des Caches und ist standardmäßig auf 16K eingestellt. Das ist ganz offensichtlich keine riesige Zahl und sollte erhöht werden, um Anwendungen entgegenzukommen, die viele Dateien laden. Der TTL-Wert hängt davon ab, wie oft sich die Speicherorte der Dateien ändern. Wenn dies selten der Fall ist, überlegen Sie den Standardwert von 120 Sekunden zu erhöhen. Ich habe diesen Wert weit höher als nur ein paar Minuten gesetzt ohne negative Auswirkungen zu erleben, aber ich wäre vorsichtig, wenn viele Dateien verschoben werden.
Wir haben bereits einige allgemeine Themengebiete abgedeckt, doch auch das Zend Framework ist ein lohnendes Ziel für Optimierungsmaßnahmen. Da das Framework auf Abwärtskompatibilität Wert legt, wurden in der aktuellen Version einige Optimierungen noch nicht vorgenommen, um diese Abwärtskompatibilität zu gewährleisten und eine möglichst niedrige PHP-Version zu unterstützen.
Das heißt aber nicht, dass wir nichts tun können!
Aufgrund der Art, wie das Zend Framework strukturiert ist, ist der Quelltext von zahllosen require_once-Statements übersät. Das klingt wahrscheinlich nicht wie eine große Angelegenheit, doch bedingt durch die Größe des Frameworks werden üblicherweise viele unnötige Dateien hochgeladen, geparst und für ihren Einsatz fertig gemacht - obwohl sie nie verwendet werden.
Verringert man die Zahl der geladenen Klassen, könnte das einen anständigen Leistungszugewinn mit sich bringen. Das wird erreicht, indem man sich PHPs autoload-Fähigkeiten zunutze macht, wonach Klassen dynamisch geladen werden, wenn sie benötigt werden (im Prinzip ist das Lazy-Loading recht ähnlich). Unnötige Klassen beim Includen zu überspringen, reduziert die Auslastung von PHP.
Bei Zend Framework gibt es eine kleine Komplikation, da das mit Abstand am häufigsten genutzte Autoload-Feature von Zend_Loader bereitgestellt wird. Zend_Loader hat seine eigene mysteriöse und versteckte Tagesordnung, nach der es unabhängig Datei-Kontrollen und andere Operationen bei jedem Autoload ausführen muss. Diese Operationen sind - bis auf einige wenige Grenzfälle - vollkommen irrelevant und sinnlos.
Mit Zend Framework 1.8.0 wurde Zend_Loader::autoload() als "missbilligtes" Feature ("deprecated") gekennzeichnet, was heißt, dass Sie es in neuen Projekten nicht mehr verwenden und zudem erwägen sollten, es vor der Veröffentlichung von Zend Framework 2.0 durch die neue Lösung Zend_Loader_Autoloader zu ersetzen.
Zend_Loader zu verwenden macht manchmal Sinn, doch da Zend Framework der extrem berechenbaren PEAR-Konvention folgt, funktioniert der folgende Code genausogut und überspringt die teureren Plausibilitätsüberprüfungen von Zend_Loader.
function __autoload($path) { include str_replace('_','/',$path) . '.php'; return $path;}Sie könnten dies auch als statische Methode für Ihre Bootstrap-Klasse erstellen.
class ZFExt_Bootstrap{ // ... public static function autoload($path) { include str_replace('_','/',$path) . '.php'; return $path; } // ... }Eine vierzeilige Funktion gegenüber einer Klasse. Wer hat noch einmal den Kampf zwischen David und Goliath gewonnen? Es sei angemerkt, dass einige Bibliotheken von Drittherstellern spezieller Behandlung bedürfen, wenn sie nicht der PEAR-Konvention folgen.
Seit Zend Framework 1.8 gibt es mit Zend_Loader_Autoloader eine neue Lösung, deren Features es wert sind übernommen zu werden, selbst wenn sie komplexer als das einfache autoload-Replacement erscheinen, das ich gerade beschrieben habe. Trotz der Komplexität der neuen Klasse können Sie Ihren Teil vom Performance-Kuchen haben, indem Sie eine kleine Änderung an der Funktionsweise von Zend_Loader_Autoload::autoload() vornehmen. Das ist möglich, da die neue Klasse es den Entwicklern erlaubt, den vorgegebenen Autoloader Zend_Loader::loadClass() durch eine eigene leichtere Funktion zu ersetzen, um all die unnötigen Dateikontrollen zu vermeiden. Falls Sie Zend_Application verwenden, müssen Sie das vor dem Bootstraping-Prozess erledigen, also in index.php.
$autoloader = Zend_Loader_Autoloader::getInstance();$autoloader->setDefaultAutoloader(array('ZFExt_Bootstrap', 'autoload'));Die Verwendung von Autoloading alleine wird die Auswirkungen all dieser require_once-Statements im Code von Zend Framework nicht aufheben. Um den größten Nutzen aus dem Autoloading zu ziehen, ist es keine schlechte Idee, einfach alle require_once-Referenzen aus den Klassendateien zu entfernen. Erledigen können Sie das mit einem Phing-Task, über die Befehlszeile oder mit einem alten PHP-Skript, dass Sie auf eine neue Kopie der Zend-Framework-Bibliothek anwenden.
Über die Befehlszeile können Sie diese Referenzen wie folgt auskommentieren:
cd path/to/ZendFramework/library find . -name '*.php' -not -wholename '*/Loader/Autoloader.php' -print0 | \ xargs -0 sed --regexp-extended --in-place 's/(require_once)/\/\/ \1/g'
Innerhalb des Frameworks gibt es ein paar Klassen, die sich in teuren Operationen ergehen. Zum Beispiel sendet Zend_Db_Tables im Hintergrund jedes Mal eine "DESCRIBE TABLE"-Abfrage, wenn Sie eine neue Instanz seines Typs erzeugen. Wenn man berücksichtigt, dass Sie bei jeder Anfrage vermutlich zumindest ein paar davon erstellen, summieren sich diese Anfragen. Ein anderes Beispiel ist Zend_Translate, dass die Quellen für die Übersetzungen immer wieder parst, wenn sie verwendet werden.
Zum Glück lassen Sie beide Komponenten einen Cache definieren, also vermeiden Sie, dass Sie sich in der Zukunft ziemlich dumm vorkommen und achten Sie darauf, dass Sie sie einsetzen.
Für Zend_Db_Table können Sie einen Cache vorgeben, indem Sie eine Intsanz von Zend_Cache an Zend_Db_Table_Abstract::setDefaultMetadataCache() übergeben. Zend_Translate bietet mit Zend_Translate::setCache() dasselbe Feature an, genauso wie Zend_Locale mit Zend_Locale::setCache(). Sie alle können in Ihrer Bootstrap konfiguriert und eingerichtet werden, damit sie für alle Anfragen verfügbar sind.
Im Bereich der Performanceoptimierung ist Caching eine wichtige Angelegenheit, da man substantielle Leistungszugewinne erzielen kann, indem man die Ergebnisse teurer Operationen über eine gewisse Zeitspanne cacht. Wenn man sich damit beschäftigt, wann man cacht, muss man sich aber auch die Frage stellen, wo man cacht.
Nehmen wir das Beispiel einer dynamischen Seite, in der die dynamischen Elemente (etwa eine stündlich aktualisierte Liste der letzten Neuigkeiten) selten aktualisiert wird. Die offensichtlichste Maßnahme wäre, die dynamischen Daten für die letzten Neuigkeiten zu cachen (wohl innerhalb eines Models oder eines View-Helfers). Da die Änderungen stündlich erfolgen, beträgt die TTL des Caches an die 3,600 Sekunden. Die dynamischen Elemente werden somit nur noch jede Stunde mit den neuen Daten aktualisiert. Doch um diesen Cache zu verwenden, müssen wir der Anwendung auftragen, dass sie die Generierung der View anstößt, die wiederum den Cache verwendet - jede Anfrage trifft die Anwendung weiterhin wie gewohnt.
Ist das wirklich notwendig? Wenn die einzigen dynamischen Elemente der Seite stündlich aktualisiert werden, warum cachen wir dann nicht die gesamte Seite für eine eine volle Stunde? Sie können Seiten mittels Zend_Cache von Ihrer Bootstrap aus cachen.
<?php class ZFExt_Bootstrap{ // ... public function run() { $this->setupEnvironment(); /** * Implementiere Page-Caching auf dem Bootstrap-Level */ $this->usePageCache(); $this->prepare(); $response = self::$frontController->dispatch(); $this->sendResponse($response); } public function usePageCache() { $frontendOptions = array( 'lifetime' => 3600, 'default_options' => array( // deaktiviere das normale Caching für alle Anfragen 'cache' => false ), // Cache die Routen zu den Index- und News-Controllern 'regexps' => array( '^/$' => array('cache' => true), '^/news/' => array('cache' => true) ) ); $cache = Zend_Cache::factory( 'Page', 'Apc', $frontendOptions ); /* * Liefere (falls vorhanden) die gecachte Seite aus und beende * das Skript. */ $cache->start(); } // ... }Aber ist diese Ebene des Caching ausreichend? Wir müssen weiterhin PHP aufrufen, um die Bootstrap zu erreichen. Somit muss PHP zumindest etwas Arbeit verrichten. Sehr wahrscheinlich muss dafür ein Apache-Prozess gestartet werden. Die schnellste Caching-Strategie ist tatsächlich, diese dynamischen Seiten für die Stunde als statische HTML-Files zu cachen, die kein PHP benötigen, in einem Setup mit "Reverse Proxies" Apache vollkommen umgehen und von leichteren Alternativen wie lighttpd oder nginx ausgeliefert werden können. Da die Anfragen nie mit der Anwendung oder der Bootstrap in Berührung kommen, wird es natürlich ein weniger komplizierter, diesen Cache zu invalidieren!!
Mit oder ohne physikalischem statischen Caching kann man als ergänzende Methode das Caching durch die Verwendung von Etag- oder Last-Modified-Headern an den Client delegieren. Das ist hilfreich, wenn man viele wiederholte Besucher hat, doch es ist nicht so leistungsfähig wie statisches HTML-Caching, wenn einmalige oder unregelmäßige Besuche die Norm sind.
Diese Diskussion illustriert, dass wir während der Etablierung von Caching in einer Anwendung unbedingt feststellen müssen, wo Caching eingesetzt werden kann, um den größten Nutzen zu erzielen. Erinnern Sie sich daran, dass es beim Caching darum geht, unnötige Prozessor- und Speicherbelastung zu vermeiden - je weiter in den äußeren Schichten einer Anwendung das Caching platziert werden kann, desto mehr Berechnungen werden vermutlich vermieden.
In einer typischen Zend-Framework-Anwendung können Sie damit rechnen, Klassen überall verstreut vorzufinden. Es ist nicht ungewöhnlich, dass Sie Klassen von so vielen verschiedenen Orten beziehen, dass Ihr finaler include_path schrecklich aussieht. Das beeinflusst die Leistung, da PHP jedes Mal, wenn Sie eine Klasse über einen relativen Pfad einbinden (sei es direkt oder über eine Autoload-Funktion) eine passende Datei finden muss, indem es über jeden registrierten include_path iteriert.
Da das nicht wünschenswert ist, müssen wir zwei simple Regeln befolgen und anwenden.
Erstens: halten Sie die Zahl Ihrer Include-Pfade möglichst klein. Installieren Sie (wo möglich) Bibliotheken und sogar das Zend Framework in gemeinsame Verzeichnisse. Da viele PHP5-Bibliotheken schon lange die PEAR-Konvention adoptiert haben, sollte das kein großes Problem darstellen. Eine Ausnahme stellen Updates von Bibliotheken dar, die zum Beispiel svn:externals unter Subversion verwenden, wenn die externe Bibliothek Dateien an einer übergeordneten Stelle aufweisen. Ein Beispiel für eine solche Ausnahme ist HTMLPurifier, das Dateien parallel zum HTMLPurifier-Verzeichnis wartet.
Behalten Sie aber abgesehen von den wenigen Ausnahmen wo möglich die Bibliotheken in einem gemeinsamen Verzeichnis. Somit können Sie statt einer Liste mit zehn Millionen Include-Pfad-Einträgen eine effizientere Liste mit maximal 2 bis 4 Orten vorhalten.
Als zweite Regel sollten Sie dafür sorgen, dass die meistgenutzten Pfade am Beginn der include-Pfad-Liste stehen. Dadurch kann man sicher sein, dass die Dateien schnell gefunden werden und das Iterieren über andere mögliche Speicherorte nur auf einige wenig genutzte Klassen beschränkt ist.
Ganz egal, wie aggressiv Sie ihre Anwendung optimieren: irgendwann wird Ihr Server an eine Grenze stoßen, wieviel Datenverkehr er verarbeiten kann. Einer der wichtigsten limitierenden Faktoren eines Servers ist die Menge des verfügbaren Speichers. Je mehr Verkehr Ihre Anwendung erzeugt, destomehr Speicher wird durch die Apache-Prozesse und MySQL konsumiert, bis der Server keine Alternative mehr hat, als auch die Festplatte als Auslagerungsspeicher ("Swap-Space") zu verwenden.
Swap-Space ist unglaublich langsam (alle Operationen auf der Festplatten bewegen sich im Vergleich zum RAM im Schneckentempo), weswegen ihn man so gut wie möglich vermeiden sollte. Wenn Apache-Prozesse auf den Auslagerungsspeicher angewiesen sind - oder noch schlimmer, wenn der übergeordnete Apache-Prozess Child-Prozesse aus dem Swap-Speicher erzeugt - dann kann das Ihre Anwendung in die Knie zwingen, was nicht gerade zu einem herausragenden Erlebnis für die Benutzer führt. Das gilt besonders für AJAX-Anwendungen, bei denen eine schnell reagierende Benutzeroberfläche extrem wichtig ist.
Die offensichtlichste Lösung für solche Serverprobleme ist, mehr Hardware ins Spiel zu bringen - ein Prozess, der auch Skalierung genannt wird. Sie könnten den RAM erhöhen, den Server durch ein leistungsstärkeres Gerät ersetzen (vertikale Skalierung) oder mehrere Server einrichten, die sich die Last aufteilen (horizontale Skalierung). Bevor Sie jedoch übereilt in irgendeine Richtung skalieren, ist es wichtig, dass Sie Ihre vorhandenen Ressourcen so effizient wie möglich nutzen, um die Investitionen in neue Hardware zu minimieren. Ja, Optimierung spart Ihnen Geld und macht Ihre Benutzer glücklicher.
Bei unserem HTTP-Server Apache gibt es einige Bereiche, die man sich ansehen kann. Die Konfigurationsdatei von Apache, für viele Entwickler ein fortdauerndes Mysterium, ist ein Ort, von dem viele Probleme mit dem Speichermanagement ausgehen. Das Problem ist, dass Apache sehr gerne seinen Teil des RAM-Kuchens hat und kein Stück davon kampflos hergibt. Das andere Problem mit Apache ist, dass er - obwohl er ein super-erfolgreicher, schneller Server ist - noch flinkere Mitbewerber hat, die weitaus weniger Speicher belegen (Ketzer, Ketzer!).
Eine Strategie, in der wir einerseits Apache optimal entsprechend der gegebenen Server-Ressourcen konfigurieren und ihn andererseits vollkommen außen vorlassen, wenn er nicht benötigt wird, kann zu dramatischen Leistungszugewinnen führen. Darüber hinaus gibt es zwei weitere Faktoren: der eine hat damit zu tun, dass man die Clients Inhalte cachen lässt und der andere ist ein Nebeneffekt des momentan stattfindenden Wechsels zu 64bit-Betriebssystemen. Fangen wir mit der Konfiguration an, bevor ich mich auf einmal am Scheiterhaufen festgebunden wiederfinde, umgeben von brennendem Holz und Menschen mit ernsten Gesichtern und Mistgabeln.
Die schlichte Wahrheit betreffend Apache ist, dass Ihr Server nur jene Zahl von Childprozessen effizient unterstützen kann, die sich im Speicher unterbringen lässt. Der klassische falsch konfigurierte Server erlaubt es zu vielen (oder umgekehrt zu wenigen) Apache-Kindern unbeaufsichtigt herumzulaufen mit der Folge, dass so viel Speicher verwendet wird, dass eine Begegnung mit dem Auslagerungsspeicher unvermeidlich wird. Die Anzahl der Apache-Childprozesse zu beherrschen und ein Auge auf immer größeren Speicherverbrauch zu haben wird Ihren Server bei maximaler Effizienz laufen lassen, ohne dass er sich ein frühes Grab schaufelt, wenn der Digg-Effekt an die Tür klopft.
Unglücklicherweise gibt es nicht die eine perfekte Apache-Konfiguration. Einige Server haben mehr Speicher als andere oder verbringen mehr Zeit damit, statische Dateien als dynamische Inhalte auszuliefern. Sie werden Ihre Konfiguration entsprechend des Profils Ihrer Anwendung und der Serversoftware anpassen und testen müssen (wir haben Apache Bench und Siege vorhin erwähnt). Die Hinweise unten sind vage Vorschläge, worauf Sie achten können, wenn Sie beginnen.
Die wichtigsten Konfigurationsoptionen für das Speichermanagement sind StartServers, MinSpareServers, MaxSpareServers, MaxClients, und MaxRequestsPerChild. Da PHP Apache gerne im Voraus forkt, benötigt jede Anfrage an den Server einen Childprozess. Zum Glück dürfen Childprozesse in der Nähe bleiben und mehrere Anfragen bedienen (somit muss man weniger warten, bis neue erzeugt werden). Jeder Childprozess verbringt also Zeit damit, herumzusitzen und einen Haufen an Speicher zu besetzen. Kurz und bändig: wenn Ihr Serverspeicher (sobald man die anderen Prozesse für MySQL, ssh, etc. abgezogen hat) genug Speicher für 40 Apache-Prozesse übrig hat, ohne auf den Swap-Space ausweichen zu müssen (siehe MaxClients), dann sollten Sie sichergehen, dass Sie nie mehr als 40 haben.
Zu berechnen, wieviele Clients man zulassen soll, ist keine leichte Aufgabe. Die einfache Berechnung lautet:
Dabei handelt es sich vielleicht um eine Überschlagsrechnung, aber Apache konsumiert je nach Szenario eine unterschiedliche Menge an RAM. Ein einfacher Zend-Framework-Request kann 17 bis 20 MB pro Prozess konsumieren (nehmen wir 40 Prozesse für einen Server mit 1GB RAM an, von denen 800 MB für Apache bereitgehalten werden). Das Ausliefern einer statischen oder gecachten Seite würde wesentlich weniger beanspruchen, 2 bis 4 MB pro Prozess. Die Konfiguration von Apache anzupassen heißt Annahmen darüber zu treffen, wie Benutzer die Anwendung verwenden, wie oft gecachte und wie oft vollkommen dynamische Seiten angefragt werden, und auf welcher Ebene Caching verwendet wird (komplett oder teilweise).
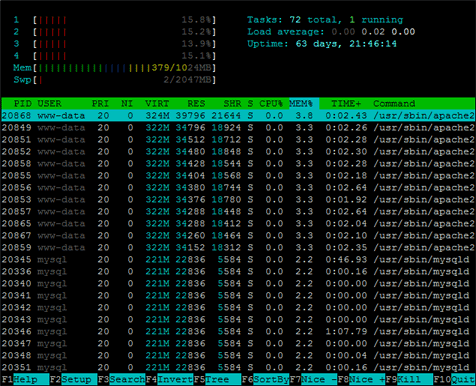
Konfigurieren Sie die obigen Einstellungen, während Sie den Speicherverbrauch beobachten (vielleicht mit einer Mischung aus top, free oder dem sehr netten htop) und den Server mittels ApacheBench und Siege mit Anfragen bombardieren. Starten Sie mit harmlosen Werten (üblicherweise den Standardeinstellungen nach der Installation). Entsprechend dem Niveau des Speicherverbrauchs können Sie anfangen zu optimieren und mehr oder weniger Childprozesse (MaxClients) mit variierenden Startpositionen (StartServers, MinSpareServers) zuzulassen. MaxRequestsPerChild beginnt üblicherweise mit einem recht hohen Wert, aber Sie sollten darauf achten, ob die Childprozesse mit der Zeit im Speicher wachsen - behalten Sie eine Einstellung bei, die Childprozesse beendet, wenn sie zu stark aufgebläht werden - immerhin ist die Absicht, potentielle Speicherlecks zu bekämpfen. Vergewissern Sie sich, dass der Konfigurationswert für ServerLimit immer MaxClients voraus ist.
Hier haben Sie eine Momentaufnahme, die htop bei der Arbeit zeigt (es sieht wesentlich netter als top aus und bietet interaktive Features).
Zu den weiteren Elementen, die Sie sich ansehen sollten, zählen KeepAlive und KeepAliveTimeout. Gehen Sie sicher, dass sie aktiviert sind, da Clients dadurch Verbindungen für mehrere HTTP-Anfragen wiederverwenden können. Wenn Ihre Besucher nicht viele weitere Anfragen stellen, sollten Sie KeepAliveTimeout natürlich auf ein Niveau einstellen welches verhindert, dass Verbindungen zu lange aufrecht erhalten werden, wenn sie stattdessen andere Clients versorgen könnten, die mehr Aufmerksamkeit fordern. Üblicherweise reicht es, wenn Sie einen Wert von 2 für KeepAliveTimout verwenden. Einige Websites mit optimiertem HTML laufen sogar besser, wenn diese Einstellung auf 1 gesetzt oder deaktiviert ist.
Als nächstes kommt jedermanns Fixpunkt - .htaccess-Dateien. Wenn Sie die Kontrolle über Ihren eigenen virtuellen Host haben, überlegen Sie sich, die Direktiven aus der .htaccess-Datei in den entsprechenden Verzeichniscontainer von http.conf oder der externen vhost-Datei zu verlegen. Dadurch muss Apache die .htaccess-Dateien nicht mehr kontinuierlich parsen.
Meine letzten Worte sind für das Apache-Modul mod_expires reserviert, das die Expire- und Cache-Control-HTTP-Header kontrolliert. Diese Header weisen Clients an, statische Inhalte zu cachen und diese Dateien nicht mehr anzufragen, bis sie veraltet sind! Das ist für Bilder, CSS, JavaScript und andere statische Inhalte sinnvoll. Diese Konfigurationsoption von Apache kann für den ganzen Server, für einzelne virtuelle Hosts oder pro Verzeichnis gesetzt werden, um feine Abstufungen vorzunehmen. Der Nutzen liegt darin, dass die Anzahl der Anfragen durch die Clients reduziert wird. Weniger Anfragen bedeuten, dass Speicher und Rechenzyklen für andere übrig bleiben.
Hier haben wir ein Beispiel, das CSS-Dateien beeinflusst und HTTP-Header hinzufügt, laut denen Dateien innerhalb dieses Verzeichnisses 30 Tage (2592000 Sekunden) nach dem Bearbeitungsdatum der Datei (M) als veraltet gelten.
<Directory /home/mrweb/public_html/example.com/css>
ExpiresActive On
ExpiresByType text/css M2592000
</Directory>
Vielleicht fällt Ihnen nach diesen Optimierungsmaßnahmen auf, dass Sie immer noch nur auf 35 bis 40 Anfragen pro Sekunde kommen, obwohl Sie so viele Apache-Prozesse einsetzen, wie im Speicher Platz finden. htop oder free bestehen aber darauf, dass Sie immer noch freien RAM haben, der untätig herumsitzt, obwohl Apache Bench daneben herumwütet. Leider übersteigt Ihre Speicherkapazität häufig weit die Fähigkeiten Ihrer CPU, wodurch ein Engpass entsteht. In diesem Szenario können Sie leider nicht viel tun, ohne in mehr CPU-Kapazitäten zu investieren, als zu überprüfen, dass Ihre Anwendung gegen eine Überbeanspruchung der CPU optimiert ist. Caching spielt hier definitiv eine Rolle. In solchen Situationen tendiere ich dazu, Festplattencaches zu Speichercaches zu migrieren (zum Beispiel, indem ich APC oder Memcached-Backends für Zend_Cache verwende). Warum nicht, wenn noch freier RAM da ist, den man sich zunutze machen kann? Speichercaches sind sehr schnell und können verwendet werden, um die Ergebnisse CPU-intensiver Operationen zu cachen (selbst wenn das Ergebnis winzig ist) und das letzte Bisschen aus der CPU herauszukitzeln.
Manchmal muss man Apache einfach umgehen. Apache ist schnell, verwendet aber wesentlich mehr Speicher und kann auch langsamer sein als einige Alternativen wie lighttpd oder nginx. In diesem Abschnitt werfen wir einen Blick darauf, wie man nginx als Reverse-Proxy für Apache verwendet. Das heißt, dass nginx an vorderster Front als HTTP-Server fungiert und im Hintergrund alle Anfragen nach dynamischen Inhalten an Apache weitergibt, während er sich selbst um alle statischen Inhalte kümmert. Das bedeutet auch, dass Apache alle Inhalte zwecks Auslieferung an nginx sendet und sich somit schneller einer anderen Anfrage zuwenden kann.
Dieser Ansatz bietet einige Vorteile. Nginx hat im Vergleich zu Apache einen winzigen Speicherbedarf, womit man mit jedem Ersatz von Apache durch nginx unmittelbar Speicher spart. Dieser Effekt tritt in Erscheinung, wenn statische Inhalte ausgeliefert werden, da nginx das schneller und leichter als Apache erledigt. Den Nutzen merkt man auch dort, wo langsame Clients häufig vorzufinden sind. Darunter versteht man jene Clients, die länger als üblich brauchen, um den Download einer Anfrage abzuschließen. Während der Client arbeitet, sitzt ein Apache-Prozess auf dem Server sekundenlang herum und wartet darauf, dass der Client fertig wird. Würden Sie es bevorzugen, wenn ein Prozess von 15MB+ für Ewigkeiten wartet oder wenn stattdessen nginx mit seinem minimalen Speicherbedarf das Warten übernimmt, während der Apache-Prozess befreit wird und sich einer weiteren Anfrage nach dynamischen Inhalten zuwenden kann? Die Antwort sollte offensichtlich sein!
Wir bleiben wie bisher in diesem Buch bei Ubuntu. Die Installation von nginx ist einfach erledigt:
sudo aptitude install nginx
Wenn Sie als root unterwegs sind, können Sie "sudo" weglassen - aber ernsthaft, warum sollten Sie root verfügbar haben?
Wenn Sie eine Umgebung mit Reverse-Proxy konfigurieren, ist es wichtig, dass Sie sich Gedanken über die Rollen von nginx und Apache machen. Apache wird nicht länger auf Port 80 lauschen, da nginx die Rolle als Front-End übernimmt. Daher sollten wir die Konfiguration von Apache ändern, damit er stattdessen zum Beispiel auf Port 8080 auf Aufträge wartet. Wir nehmen die Anpassung in der Hauptkonfigurationsdatei oder - falls vorhanden - in ports.conf vor.
NameVirtualHost *:8080
Listen 8080
<IfModule mod_ssl.c>
Listen 443
</IfModule>
Wir sollten zudem die Konfiguration der virtuellen Hosts ändern, damit sie ebenfalls Port 8080 verwenden.
<VirtualHost *:8080> ServerAdmin [email protected] ServerName example.com.com ServerAlias www.example.com DocumentRoot /var/www </VirtualHost>
Nun wenden wir uns nginx zu. Sie verwenden dort eine Konfiguration im Ubuntu-Stil mit einer Hauptkonfigurationsdatei und Unterkonfigurationen für die virtuellen Hosts (nginx-Server). Hier kommt es bis zu einem gewissen Grad zu Duplizierungen, da nginx häufig einen passenden "Server"-Konfigurationscontainer für jeden virtuellen Host in Apache braucht, für den wir das Reverse-Proxy-Setup verwenden möchten. Hier haben wir eine einfache Hauptkonfigurationsdatei, die in Ubuntu unter /etc/nginx/nginx.conf gespeichert wird.
# Ubuntu Intrepid
user www-data www-data;
worker_processes 2;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
use epoll;
}
http {
server_names_hash_bucket_size 64;
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log;
client_body_temp_path /var/spool/nginx-client-body 1 2;
client_max_body_size 32m;
client_body_buffer_size 128k;
server_tokens off;
sendfile on;
tcp_nopush on;
tcp_nodelay off;
keepalive_timeout 2;
# Binde die Konfiguration der virtuellen Hosts für die aktivierten
# Sites ein.
include /etc/nginx/sites-enabled/*;
}
Nginx hat tendenziell den Ruf einer undurchsichtigen Konfigurationsdokumentation, da alle Originaltexte in Russisch verfasst sind. Englische Übersetzungen werden auf http://wiki.codemongers.com/ gepflegt. Sie finden hier keine Einstellung MaxClients; der Wert ergibt sich aus dem Produkt von worker_processes und worker_connections. Die Dokumentation deckt die anderen hier verwendeten Optionen ab. Viele werden Ihnen von Apache bekannt vorkommen.
Am Ende dieser Konfiguration oder in einer seperaten Datei im Verzeichnis /etc/nginx/sites-enabled/ können Sie eine Konfiguration pro Server erstellen. Diese Dateien sind verwandt mit der Konfiguration der virtuellen Hosts von Apache.
server {
listen 80;
server_name example.com www.example.com;
# Standard-Konfiguration für Gzip (setze Ausnahmen in den locations)
gzip on;
gzip_comp_level 2;
gzip_proxied any;
gzip_types text/plain text/html text/css text/xml application/xml application/xml+rss \
application/xml+atom text/javascript application/x-javascript application/javascript;
# Behandle hier statische Inhalte
location ~* ^.+\.(jpg|jpeg|gif|png|ico)$ {
root /var/www;
access_log off;
gzip off;
expires 30d;
}
location ~* ^.+\.(css|js)$ {
root /var/www;
access_log off;
expires 1d;
}
location ~* ^.+\.(pdf|gz|bz2|exe|rar|zip|7z)$ {
root /var/www;
gzip off;
}
# Leite nicht-statische Anfragen an Apache weiter
location / {
# Proxy-Konfiguration
proxy_pass http://your-servers-ip:8080/;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_max_temp_file_size 0;
client_max_body_size 10m;
client_body_buffer_size 128k;
proxy_connect_timeout 90;
proxy_send_timeout 90;
proxy_read_timeout 90;
proxy_buffer_size 4k;
proxy_buffers 4 32k;
proxy_busy_buffers_size 64k;
proxy_temp_file_write_size 64k;
}
}
Diese Serverkonfiguration zeigt auf denselben Document-Root wie unser früherer virtueller Host in Apache. Denken Sie sich nginx als einen Filter und ein Gateway. Die allererste Zeile der Konfiguration aktiviert als Standardeinstellung die Komprimierung der Inhalte mittels gzip. Danach habe ich drei location-Container eingerichtet, die reguläre Ausdrücke anwenden, um Anfragen für bestimmte Dateitypen abzufangen. Wird eine der Regeln erfüllt, werden die Dateien direkt von nginx ausgeliefert, ohne dass Apache deswegen belästigt wird. Ich habe nginx auch abhängig vom Dateityp mitgeteilt, ob der Inhalt mit gzip komprimiert werden soll oder nicht, und welche Expires-Header gesetzt werden sollen (falls überhaupt). Diese drei Container sorgen dafür, dass Apache nie teuren Speicher für statische Inhalte verschwenden muss, welche nginx an seiner Stelle ausliefern kann.
Der vierte und letzte Container gilt für alles, was die vorherigen Container nicht abgefangen haben: dynamische Inhalte und statische Dateien, auf welche die regulären Ausdrücke von nginx nicht zutreffen. In diesem Fall konfigurieren wir nginx so, dass die Anfragen auf Port 8080 der lokalen Server-IP weitergeleitet werden, wo Apache lauscht. Sobald Apache die Anfrage erledigt hat, wird sie sofort zu nginx zurückgesendet (womit Apache wieder frei ist, etwas anderes zu erledigen).
Wir haben die ganze Bandbreite von Optimierungstipps für Zend-Framework-Anwendungen durchgemacht und obendrein noch ein paar Hardwareangelegenheiten gestreift. Es gibt zweifellos noch viele andere Optimierungstipps, die hier nicht erwähnt wurden - es handelt sich also (wie Sie sehen) können um ein umfangreiches Themengebiet.
Die grundlegende Botschaft, die sich durch diesen Anhang zieht ist, dass man für Optimierungen die Fortschritte gegenüber einem gewissen Ausgangspunkt messen muss. Dabei kann es sich um einen Performance-Benchmark oder andere Metriken handeln. Man kann Optimierungspotentiale nur dann identifizieren und ihren potentiellen Ertrag beurteilen, wenn man eine robuste Methodologie anwendet. Sie sollten es vermeiden, Ihre Zeit mit willkürlichen Optimierungsmaßnahmen zu verschwenden, die nur minimale Zugewinne bringen.
![[Achtung]](images/docimg/caution.png)